Alphabetical Sort in JavaScript (and InDesign)
October 26, 2010 | Tips | en | fr
Surprisingly, JavaScript offers no easy way to alphabetize words in relevant order. Although the Array.sort() method is known to perform, by default, a lexicographical sort, you will find very quickly that the result is wrong in most real-life situations. Actually, the internal mechanism of JS sorting is confined to compare Unicode characters by their code points, so 'Z' (U+005A) comes before 'e' (U+0065), which itself comes before 'ç' (U+00E7), etc. Also, you have all noted with vexation that InDesign does not offer any alphabetical sort feature! Here is an experimental tool to help restore order in Latin alphabets.
The well known Unicode Collation Algorithm (UCA) clearly sets out the implications of lexicographic sorting:
“Collation implementations must deal with the often-complex linguistic conventions that communities of people have developed over the centuries for ordering text in their language, and provide for common customizations based on user preferences. [...] Many people see the Unicode code charts, and expect the characters in their language to be in the ‘correct’ order in the code charts. Because collation varies by language —not just by script—, it is not possible to arrange code points for characters so that simple binary string comparison produces the desired collation order for all languages. Because multi-level sorting is a requirement, it is not even possible to arrange code points for characters so that simple binary string comparison produces the desired collation order for any particular language. Separate data tables are required for correct sorting order.”

That said, because performance is critical in scripting, the main problem is to synthesize an efficient algorithm without drowning our code in the infinite ocean of Unicode charts. I do not think it would be reasonable to import the whole UCA database in an InDesign script! And even then, we should still implement the “tailoring syntax” to get linguistically-accurate collation for each language —which generally involves integrating extra building blocks from the Unicode Common Locale Data Repository.
Seeking a Midpoint
To my knowledge, Peter Kahrel is the only author who has offered a practical and robust solution to the alphabetical ordering problem. Its “Language-Aware Paragraph Sorter” is an amazing InDesign script that supports several languages and features a bunch of powerful options: Letter by letter vs. Word by word sort, Character style filtering, Retrograde sort, Delete duplicates, etc. In addition, Peter invented a simple and elegant tailoring syntax to customize or add new language collation rules:
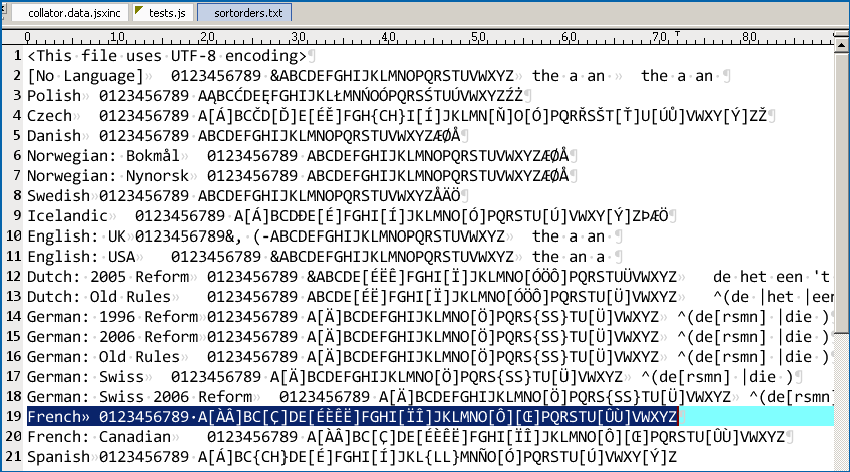
Note. — Non-English users may experience difficulty in addressing the language names from the default sortorders.txt file which is provided with the original script. I guess this is due to the localized Application.languagesWithVendors collection that the script internally invokes. So, to let the script recognize language names according to your specific InDesign locale, edit sortorders.txt and replace each language name —first field of the table— by the corresponding localized string. For example, [No Language] should be changed to [Aucune langue] in a French UI.
Inspired by Peter's script, I then tried to create a JavaScript component that I can use for my own projects whenever I need to perform a language-aware sort on a string list. The idea was to implement a kind of simplified collation algorithm, for Latin scripts only, based on the European Ordering Rules (EOR). I wanted to support any character of the Unicode Latin blocks, including extended sets, special forms and some of the IPA letters that we can bind to the basic alphabet. I also wanted to manage multilevel collation features, diacritics and case discrimination. And of course language tailoring.
The TCollator Interface
My quest has led to an experimental object, TCollator, which incorporates the maximum functionality without depending on the UCA database. I mainly referred to three resources: the “Advanced Character Search Utility” of BabelMap (great Unicode browser from Andrew West), the Mimer SQL Unicode Collation Charts, and a number of Wikipedia articles within the “Languages” and “Collation” categories, especially “Collating sequence”.
TCollator is a minimal library. You just need to include the file at the beginning of your own script by using :
#include 'collator.jsxinc' // Here your code...
That's it! The library only creates a variable named TCollator, which behaves as an interface. All methods are static, you won't create instances. Let's see how to use it in a simple example:
// My first script using TCollator #include 'collator.jsxinc' var arr = ["HLM","ÉDF","muze","où","œuf", "oval","muß","à-ha","a-ha"]; // Default JS sort arr.sort(); alert( "Default JS sort:\r\r" + arr.join('\r') ); // Using TCollator arr.sort(TCollator.compare); alert( "Using TCollator:\r\r" + arr.join('\r') );
Result:
, using TCollator (right)")
In the above snippet, the important statement is obviously:
arr.sort(TCollator.compare).
TCollator.compare is a static property referring to a function, and we pass this function to arr.sort(). Then, the Array.sort method no longer invokes the internal JavaScript comparison routine, it rather calls our TCollator.compare routine, which compares two strings, taking care of advanced collation settings.
Thus, while JS wrongly considers the word "muze" comes before "muß" ( "muze" < "muß" ! ), the TCollator.compare function gives the opposite —and correct— answer:
var cmp = TCollator.compare("muß","muze") ; if( cmp < 0 ) alert( "muß < muze"); if( cmp > 0 ) alert( "muß > muze"); if( cmp == 0 ) alert( "muß == muze"); // => muß < muze
How does it work? Basically, TCollator hosts a kind of database that stores a number of details describing Latin characters. The component knows that 'ß' (U+00DF) is a lowercase letter which is —in some respect— equivalent to the 'ss' digram. You can query that knowledge base by using the TCollator.charInfos() utility:
#include 'collator.jsxinc'; alert( TCollator.charInfos("ß") );
Result:
 utility.")
TCollator.charInfos(myCharacter) returns an object that packs various informations about the submitted character:
| PROPERTY | TYPE | DESCRIPTION |
|---|---|---|
| case | string | One of: "LOWERCASE", "TITLECASE", "UPPERCASE", "SMALLCAP". |
| character | string | The submitted character itself. |
| collationInfo | string | Short details about the collation process. |
| diacritics | array | An array of strings among: "ACUTE", "GRAVE", "BREVE", "CIRCUMFLEX", "CARON", "RING", "DIAERESIS", "DOUBLE ACCENT", "TILDE", "DOT", "CEDILLA", "OGONEK", "MACRON", "STROKE", "HOOK", "SWITCH", "MODIFIER", "SPECIAL". |
| expanded | string | Contains the basic decomposed form of a multigram. E.g.: U+00E6 -> ae, U+01C4 -> DZ, U+00DF -> ss, U+FB03 -> ffi |
| group | string | One of: "LATIN", "SPECIAL", "NUMERAL", "PUNCTUATION" |
| isMultigram | bool | Indicates whether the character is a digram, a trigram, a ligature. |
| isSupported | bool | Is the character supported by TCollation? |
| kind | string | Base class of the letter. |
| unicode | string | Codepoint in the form "UUUU" (e.g. "012A"). |
Note. — The returned object also implements a customized toString() method which allows to easily display the details on screen through alert(). If you plan to use TCollator.charInfos() in your script, remember to check the returnedObj.isSupported property before further processing.
Refine Collation Rules
TCollator supports about 1200 characters, mostly Latin letters. Whenever possible, a character is converted and reclassified among the basic A-Z alphabet, thereby giving it a default ordering weight during the comparison. It generally produces very good results, even when your list contains foreign words having unusual characters or diacritics. TCollator performs by default a level 3 collation, which means it discriminates against diacritics and case as recommended by the EOR specification. For example, sorting the array ["boc", "BÔB", "bõb", "bob","BOB","bôb", "BOA"] through TCollator.compare will result in the following order:
BOA bob BOB bòb bôb BÔB bõb boc
If you do not need such refinements, you can improve performance by reducing the collation level, using the TCollation.reset() method:
TCollator.reset( langCode , level ).
• langCode (String; Default: "DEF"). One of the codes returned by TCollator.getLocales() (see below).
• level (Number; Default: 3): An integer in [0,1,2,3]:
| LEVEL | DESCRIPTION |
|---|---|
| 0 | Basic level which won't distinguish digits, case, and diacritics (except those isolated by the locale alphabet). Therefore by default: õ = ò = O (whatever the case) and: 0 = 1 = 2 ... |
| 1 | Similar to LEVEL0, but digits are distinguished: 0 < 1 < 2 ... |
| 2 | Applies LEVEL1, then applies European Ordering Rules on diacritics and special forms that aren't supported by the locale alphabet: bob < bòb < bôb < bõb ... |
| 3 | Applies LEVEL2, then discriminates against case if needed: bob < BOB < bôb < BÔB ... |
Note by example that the Dz character (U+01F2 – CAPITAL LETTER D WITH SMALL LETTER Z) is parsed by default as a titlecased digram based on D and expanded as "Dz". (Use TCollator.charInfos("\u01F2") to get the details.) This means that unless a language isolates this character as a single alphabetic letter —like in Slovak,— TCollator will regard U+01F2 as strictly equivalent to "Dz". Which, at level 3, results in:
dz < U+01F2 = Dz < DZ
The first argument of TCollator.reset(langCode,level) is defaulted to "DEF", which implements a generic mechanism that will suit most Latin-derived scripts, or especially a multilingual lexicon. However, you may need to apply the rules of a specific language. This is crucial in alphabets that introduce extra letters or treat certain digraphs as separate letters. For example, in the Danish and Norwegian alphabets, Æ, Ø, and Å collate after Z, and Aa collates as an equivalent to Å. Until 1997, Spanish treated CH and LL digraphs as single level-1 letters, while Ñ as a specific letter still collates after N.
Therefore, TCollator supports about forty alphabets. Each is associated with a code of two or three letters that you can pass in TCollator.reset() to setup the collation algorithm for that specific language.
Note. — To restore the generic mechanism, use:
TCollator.reset('DEF'), or simply TCollator.reset().
The full list of supported alphabets / languages is returned in an Array by TCollator.getLocales(). Each array's element is itself an array of two strings: first the language name, then the language code.
| NAME | CODE | NAME | CODE |
|---|---|---|---|
| [Default] | DEF | Indonesian | DEF |
| Albanian | SQ | Irish Gaelic | DEF |
| Basque | ES2 | Italian | DEF |
| Bosnian | BCS | Kurdish (Hawar) | KU |
| Breton | BR | Latvian | LV |
| Croatian | BCS | Lithuanian | LT |
| Czech | CS | Luxembourgish | DEF |
| Danish | DNA | Malay | DEF |
| Dutch (IJ=Y) | NL1 | Maltese | MT |
| Dutch (Modern) | NL2 | Moldavian | RO |
| English | DEF | Norwegian | DNA |
| Esperanto | EO | Polish | PL |
| Estonian | ET | Portuguese | DEF |
| Faroese | FO | Romanian | RO |
| Filipino (Modern) | TL | Serbian | BCS |
| Finnish (Multilingual) | FI2 | Slovak | SK |
| Finnish (Official) | FI1 | Slovene | SL |
| French | DEF | Spanish (Modern) | ES2 |
| Frisian | FY | Spanish (Traditional) | ES1 |
| German (Decompose umlauts) | DE2 | Swedish (Modern) | SV |
| German (Dictionary) | DEF | Swedish (V=W) | FI1 |
| Greenlandic | KL | Turkish | TR |
| Hungarian | HU | Turkmen | TK |
| Icelandic | IS | Welsh | CY |
As an illustration, let's use TCollator to sort a Norwegian word list:
#include 'collator.jsxinc'; // Setup the collator to: Norwegian / Level 3 TCollator.reset('DNA',3); var myStrings = ["åbner","brænder","jeg","altså","ordet", "vild","bryst","ære","øje","brød","fjord"]; myStrings.sort(TCollator.compare); alert( myStrings.join('\r') ); /* RESULT: ======== altså bryst brænder brød fjord jeg ordet vild ære øje åbner ======== */
Sample InDesign Script
Here is another simple script that uses TCollator to quickly extract and order a word list from the selected text in the active document:
#include 'collator.jsxinc' function alphaSort() { var s = app.selection, i, t, str; if( !s.length ) return false; if( !('contents' in s=s[0]) ) { if( !('parentStory' in s) ) return false; s = s.parentStory; } s = s.contents. replace(/[\s\.,;:!?]+/g,'|'). split('|'); if( s.length > 1000 ) s.length = 1000; s.sort(TCollator.compare); i = s.length; t = false; while( i-- ) { str = s[i]; if( str && str!=t) { t = str; continue; } s.splice(i,1); } return (s.length && s)||false; } var res = alphaSort(); if( false===res ) alert( "Please select some text!" ); else alert( "Alphabetical Sort (default settings):\r\r" + res.join(' | ') );
Recall that TCollator is designed as a primitive tool to develop more complex scripts. It does not in itself interacts with the InDesign UI (so you probably could reuse it in other CS ExtendScript environments). If you want to sort paragraphs in a document, use Peter Kahrel's script, or base your own code on the TCollator brick.
Disclaimer
TCollator is an experimental tool, currently in beta. I definitely need feedback from speakers in the various supported languages. I cannot guarantee that the collation algorithm complies in all respects cultural conventions and/or lexicographical specific rules.
TCollator manages an internal cache in order to maintain acceptable performance with lists containing about a thousand terms. If you experience a slowdown after several successive Array.sort(TCollator.compare) within the same script process, use TCollator.reset to empty the cache.

Comments
Excellent work (as usual)!
Thanks for your support.
@+
Marc
This is great, Marc, it works very well, even in this beta version. And thanks for that comment on localised language names, I added a note about that.
Peter
Marc, bien que comprenant un concept sur dix, j'ai plaisir à te lire. Je comprends que certains cherchent à utiliser tes multiples talents car c'est drôle et superbement bien écrit.
Bref, même en expliquant un machin ardu de chez ARDU, tu arrives à me faire sourire et me donner envie de tout lire (alors que, voir le point 1…!).
Marc,
Have you considered a mode that ignores all diacritics? For instance, suppose you have a book written in English and that you need an author index. The index would be sorted as if there were no diacritics at all, ignoring the rules of any language. So Łukasiewicz would be sorted among all other names starting with an L, not separately.
Peter
Hi Peter,
TCollator should do exactly what you need, unless you set up a specific language. The default mechanism treats Ł as L (at the first level).
So if you sort ["Lu", "Łu", "ło", "La", "Łe", "Ło", "lo"] through TCollator.compare, you get:
La < Łe < lo < ło < Ło < Lu < Łu
Diacritics are only distinguished at level 2 (Lu < Łu), but L and Ł are regarded as the same letter at level 1.
If you don't want to apply any sublevel order, use TCollator.reset('DEF',0). In this case, the previous list may be sorted as below:
La < Łe < ło = Ło = lo < Łu = Lu
Here TCollator does not see any difference between ło, Ło and lo, so these words can appear in any order.
Anyway, TCollator regards Ł and L as two distinct first-level letters *ONLY* if you load the POLISH alphabet ('PL'):
TCollator.reset('PL');
Then my previous example will result in:
La < lo < Lu < Łe < ło < Ło < Łu
To conclude, the default configuration of TCollator is usually the good one to sort foreign words in English. As you expect, “Łukasiewicz would be sorted among all other names starting with an L, not separately.”
@+
Marc
Ah, excellent, thanks very much.
Peter
That sounds great...! Testing it now. Quesiton is: how do I implement it for, let's say, index generations or TOCs? Will I need to re-order my lists after they are generated or things can be done in the progress.
Michael
Hi Michael,
Can you rephrase, I don't understand your problem.
Note. — TCollator.compare simply provides a comparison function which you can typically use in JS Array.sort(). This is not a DOM-level utility.
@+
Marc
I tried this in Indesign extendscript and did not get what I expected, a < b
var a = "4MX692";
var b = "9ME100";
TCollator.reset();
var cmp = TCollator.compare(a,b) ;
if( cmp < 0 ) $.writeln( "a < b");
if( cmp > 0 ) $.writeln( "a > b");
if( cmp == 0 ) $.writeln( "a == b");
Hi Marc,
I implemented the collator with my index-sorter script and it works smoothly. So thank you. But... is there a way to extend it to non-Latin languages? Also, is there a way to call back a sorting character group - e.g. I'm sorting by A but then letters A acute, A grave, A tilde get sorted in the same group. Is there a way to see which letters comprise this group. Michael
@jamie
[Sorry for the delay.]
The fact that:
TCollator.compare('4MX692','9ME100') > 0
sounds like a bug at first sight but this is because I've misdocumented the LEVEL 1 comparison. (Sorry about that.)
Actually, TCollator is *in no case* intended to compare numbers (or strings that contain digits). It can only *discriminate* digits, which is not the same thing.
To understand why you did not get what you expected, keep in mind that each level has its own ‘weight’ and that comparison levels are applied successively. TCollator compares A and B at the (n+1)th level if, and only if, A equals B at the previous level.
So, at the very first level "4MX692" and "9ME100" are just seen as ".MX..." and ".ME..." (where each dot means something like: “there is a numeral character here.”) The comparison routine then returns a positive flag—as "MX" > "ME"—and the next level is not performed because the comparison is successful.
Anyway, if you need to sort numbers, use the basic comparison routine:
function(a,b){return a-b;}
If you need to sort ASCII alphanumeric strings—such as product references—use the default Array.sort() routine with no argument, or implement a custom comparator in the case where specific sequences of digits should be parsed as actual numbers. Depending on your requirements, parseInt() or parseFloat() could be helpful.
@+
Marc
@mikez
Thanks for your feedback.
> is there a way to extend [TCollator] to non-Latin languages?
Probably yes, but not from the outside of the ‘library.’ What I did with almost 1200 Latin characters could be done with other Unicode sets. Behind the scene, TCollator relies on a kind of database whose fields are stored through binary flags. But this is a very customized syntax and I'm not sure we can transpose that system to any language.
> Also, is there a way to call back a sorting character
> group - e.g. I'm sorting by A but then letters A acute,
> A grave, A tilde get sorted in the same group. Is there
> a way to see which letters comprise this group.
The `TCollator.charInfos()` helper returns an object that may help you. In particular, the `kind` property gives you the group name of the supplied character. Not sure this is what you're looking after.
E.g.:
alert( TCollator.charInfos('Ã').kind );
displays 'A'.
@+
Marc
Hi Marc,
Thanks for previous responses. I have been using collator for some time and here is what I ran into.
I have an index that lists:
Presession37->75
Presession37->214
Presession37->215
Presession37->366
Presession37->771
Presession37->900
Presession37->1237
Presession38->1070
Presession38->1241
Presession38->1242
Presession38->1243
Presession37<2>alter-isand->1238
Presession38<2>alter-isand->1244
Presession37<2>backtrackand->509
Presession37<2>clearingacaseand->1239
Presession37<2>Clearingrundownand->772
Presession37<2>description->216
Presession37<2>E-Meterand->684
Presession37<2>FailedHelpand->217
Presession37<2>Formula13and->218
Presession37<2>Formulasand->510
Presession37<2>gettingin->1065
Presession37<2>invertedcommunicationand->511
Presession37<2>IsthereanyquestionIshouldn’taskyou?and->773
Presession37<2>justificationsand->219
Presession37<2>objectof->512
Presession37<2>presenttimeproblemsand->220
Presession37<2>Presession1and->774
Presession37<2>PTproblemsand->1066
Presession38<2>runningaDianeticAssist->1245
Presession37<2>sensitivity16and->76
Presession37<2>sensitivity16and->775
Presession37<2>startingof,ModelSessionand->1067
Presession37<2>tryingtorunallcasewith->1068
Presession37<2>withholdsand->221
Presession37<2>withholdsand<3>gettingoff->776
Presession37<2>withholdsand<3>pulling->1240
Presession37<2>withholdsand<3>stoppingacase->1069
Presession1<2>description->211
Presession1<2>Help,Control,Communicate,Interestand->212
Presession1<2>interestinScientologyand->770
Presession1<2>useofinauditing->213
somehow i can't make collator sort it by
Pressession1, Presession37, Presession38.
What could be the problem.
Michael
Hi mikez,
As previously said, TCollator is really not intended to sort numeral and/or markup-based data. Its main purpose is to properly alphabetize latin words. Specific syntax requires specific sort routine.
A possibility is to create your own compare() function to precompute or filter special fields (such as numbers or tags). Then you can use TCollator.compare *within* that function to refine the comparison on lexical entries.
@+
Marc
Trop de la balle !
Merci.